The heart of Aspect-based Sentiment Analysis (ABSA) task is how to connect aspects with their respective opinion words effectively. In order to get their connection, we can compute their coefficient.
If we view aspect words as a root node, other words in the same sentence as its child nodes, we can compute their coefficient by this article:
Computing the Coefficient Between Parent Node and Child Nodes
Usually, we can use attention mechanisms to compute coefficient. For example:
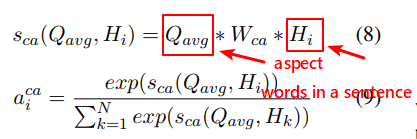
Here \(Q_{avg}\) is the vector of aspect words, \(H_i\) is the vector of each word in a sentence. We can use an attention mechanism to compute their coefficient.
We usually can get \(Q_{avg}\) and \(H_i\) by two independent networks, such as LSTM or BiLSTM.
Problem in computing coefficient using attention mechanisms?
We can find that the attention mechanism is only a softmax function. It can not determine the affection in different position. For example:
So delicious was the noodles but terrible vegetables
As to aspect word noodles, word terrible is closer to it than word delicious. Attention mechanism may get a higher score on word terrible than delicious.
Softmax function can not determine the difference with different position.
In order to fix this problem, we can use dependency tree to add the syntactic structure of a sentence to improve the computation. Dependency-based parse trees can be used to provide more comprehensive syntactic information.