We can input a text sequence to bert model for classification. However, if this text sequence has a target text or object, how to use bert?
For example:
a document has a title, we need to use title and document content for document classification.
In aspect-level sentiment analysis, a sententce has an aspect, we should use aspect and sentence for sentiment classification.
In document review sentiment analysis, we may use a user and his document for sentiment classification.
Here title, aspect and user is our target.
In article: An Introduction to Bert Combine Multiple Features to Classification we can get a method to solve this problem.
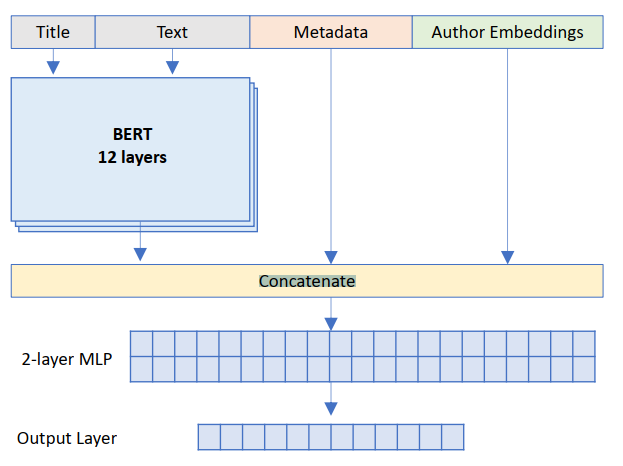
We can concentrate target and text for bert. As figure above, we can use title + text for bert classification.
In the same way, we can use aspect+sentence or user+document for classification in bert.
However, paper UserIdentifier: Implicit User Representations for Simple and Effective Personalized Sentiment Analysis gives us more detail.
As to user, how can we use a text sequence to represent a user? User id or username?
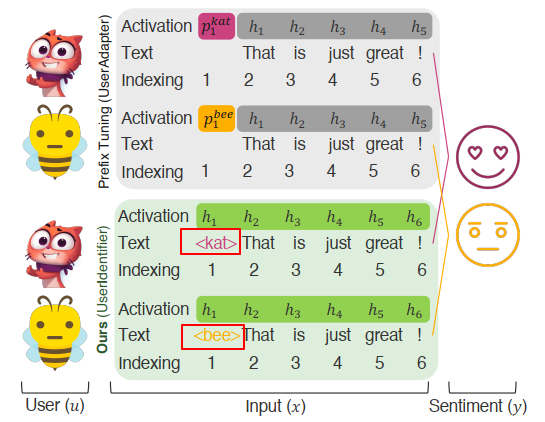
This paper proposed some ways to encode a user. They are:
- username
- a unique number, from 1 to N
- L independent and identically distributed samples from the set of digits (0 to 9)
- L Random sequence of tokens with nonalphanumeric characters
- Random sequence of all tokens (Rand. All): This scenario draws L i.i.d samples from the set of all available tokens in the tokenizer vocabulary.
Note: L length sequence is generated through uniformly sampling from the tokenizer vocabulary.
From the result, we can find: Rand.All is the best, L = 10.
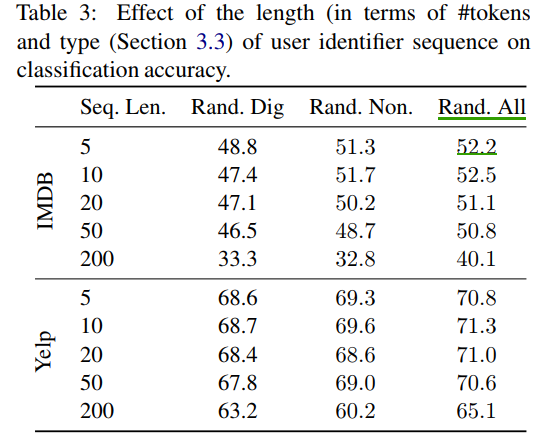
Note: Although we can train N user embedding, N is the number of user count. However, it is worse than method above.