Bert model is widely used in many NLP tasks. Bert inputs is a sequence, we can get inputs from a vocabulary. However, if we want to fuse more features to bert inpputs. How to do?
Paper PLOME: Pre-training with Misspelled Knowledge for Chinese Spelling Correction proposed a method to incorporate chinese phonic and shape to bert inputs, which means there are four types of features will be inputed into Bert model, they are:
- character embedding
- position embedding
- phonic embedding
- shape embedding
How to generate chinese phonic embedding and shape embedding?
In this paper, chinese phonic embedding and shape embedding is the last hidden output of a GRU network.
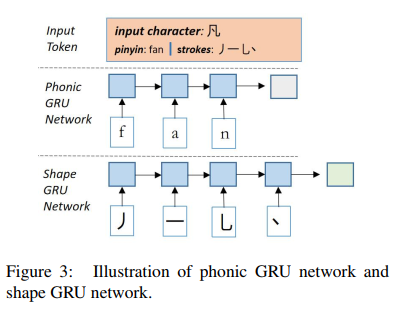
In order to get the pinphonics (also known as pinyin) of a chinese character, we can view this tutorial:
Python Convert Chinese String to Pinyin: A Step Guide – Python Tutorial
We also can use use the Unihan database and Chaizi database to get chinese pinphonics and shape introduced in this paper.
How to incorporate chinese phonic embedding and shape embedding into bert inputs?
This paper use sum method, which means we will sum four types of embeddings as to final bert inputs.
For example:
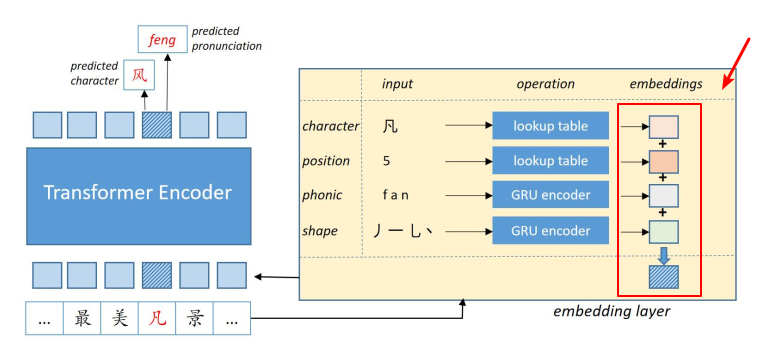
It is easy to understand.