When building an AI model, we often use an auxiliary task to improve our main task performance. In this article, we will introduce three basic models.
Paper: Toxic Speech and Speech Emotions: Investigations of Audio-based Modeling and Intercorrelations proposed these three models.
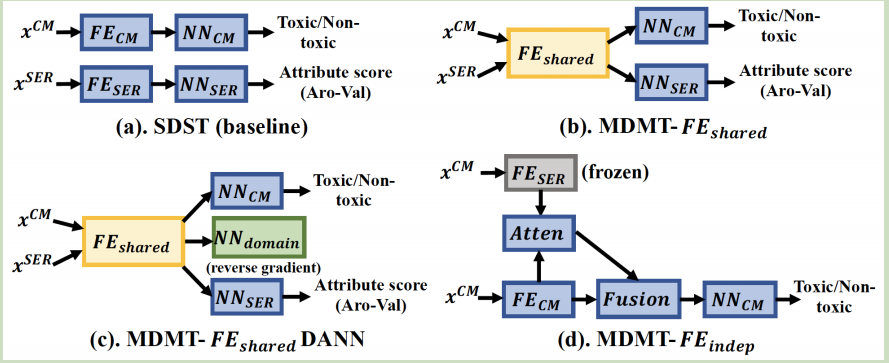
Here CM is our main task, SER is the auxiliary task.
SDST: we train our main task and auxiliary task separately, two tasks do not share any weights.
MDMT-FE_share: the main task CM and auxiliary task SER share the same encoder FE_share. This kind of model structure is common used in may multi-task learning.
MDMT-FE_sharedDANN: Add a domain classification based on MDMT-FE_share
MDMT-FE_indep: Pretrain the auxiliary task SER and frozen its weights. Then, use attention to fuse latent auxiliary task feature and main task CM feature.
Which model have the best performance?
In most situation, MDMT-FE_share will get a better performance than SDST. However, it does not in some task.
From this paper, we can find:
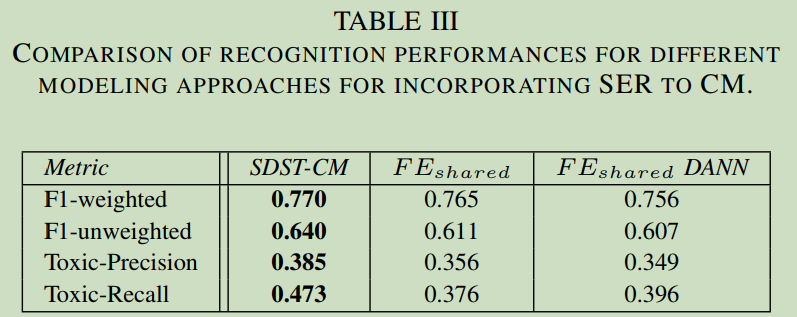
Basic SDST model structure gets the best performance.
It means the auxiliary task may hurt the performance of main task, we need to notice when we are selecting auxiliary task.
How about MDMT-FE_indep model structure?
We can find:
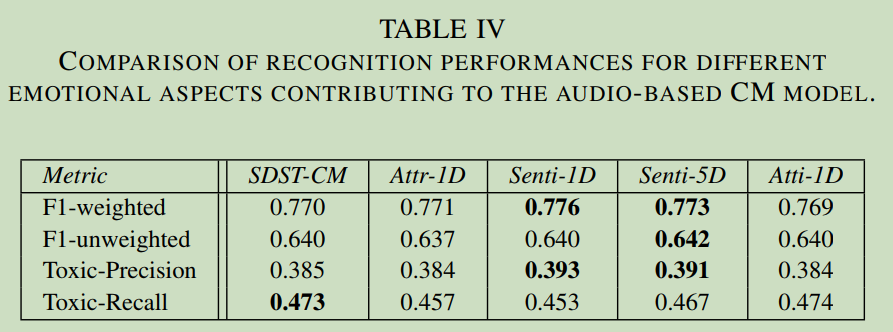
This structure have little performance on the main task.
From this paper, we can find: if we select a bad auxiliary task, it may hurt our main task. Even if we froze auxiliary task network, it has almost no effect with our main task.