There are a lot of linguistic knowledge and sentiment resources nowadays. For example: sentiment lexicons. We can add these resources to improve sentiment classification.
Here is a paper on using cnn and sentiment lexicon for this task.
CNN + Sentiment Lexicon for Sentiment Analysis
Multi-channel Features for Sentiment Classification
We can view different knowlege or resources as different channel features. The key point for using these additional features to improve the model performance is how to use these multi-channel features in your model.
We can use three basic methods, here is an example:
3 Methods to Incorporate Multiple Features in Deep Learning
In paper: Bidirectional LSTM with self-attention mechanism and multi-channel features for sentiment classification use a different method.
Look at the architecture of the model in this paper.
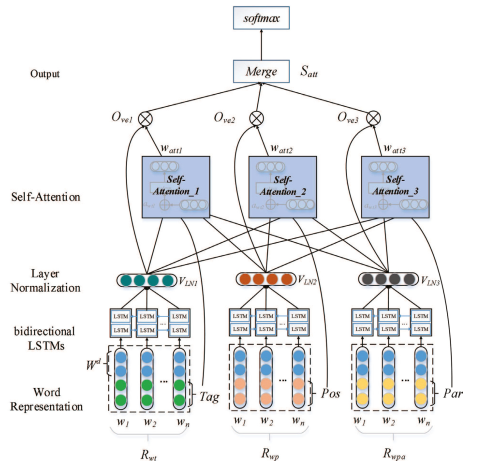
In this paper, word embeddings, part-of-speech feature , position feature and dependency parsing feature are used.
From image above we can find:
As to model inputs, additional features are concatenated with word embeddings. In this paper, we will get three feature channels.
Of course, we also can concatenate all word embedding and other features on a singel channel. It means the model input will be: [word embedding vector, part-of-speech vector, postion vector, dependency parsing vector]. The effect of this model will much worse than 3 channels.
Self-attention in Multi-channel Features
We usually compute self-attention on each channel separately. Finally, we will merge all final vector on each channel to make classification. However, this paper use a different one.
At word layer, it used a crossover method.

Here \(V_{LN1}\) is normalized output of BiLSTM, \(Tag^m\) is the part-of-speech feature, \(V_{LN2}\) and \(V_{LN3} are the normalized output of BiLSTM with additional position and dependence parsing feature.
We can find there are two key poits:
- Concatenating the inputs and the normalized outputs of BiLSTM for self-attention computation. This computation is better than only using the normalized outputs.
- Transferring the concatenated vector of other additinal feature outputs for self-attention computation.
This paper evaluated the performance of different features on self-attention, we can find: