Embedding attention is proposed in paper: Lexicon Integrated CNN Models with Attention for Sentiment Analysis. In this note, we will introduce it.
The structure of embedding attention
Embedding attention looks like:
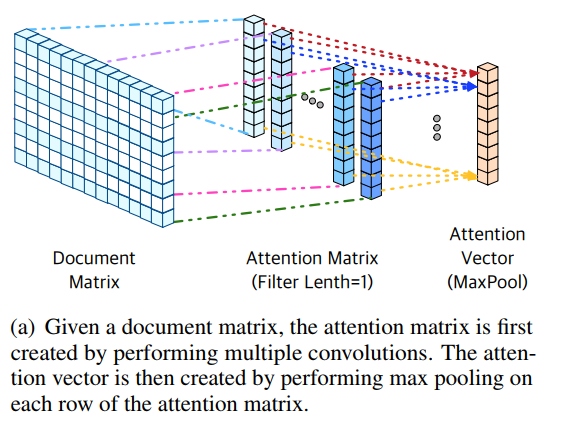
In embedding attention, the key point is: convolution and max pooling.
How to implement embedding attention?
Here are steps:
1. Apply \(m\)-number of convolutions with the filter length 1 to the document matrix s\in R^{n*d}.
For example, in bilstm, we may get an output with the shape 32* 50* 200
Here batch size is 32. n = 50, d = 200, we can suppose the \(n\) is the number of sentences in a document.
In Conv2D, we can reshape the output to [32, 50, 200, 1]
Supporse \(m = 20\), the filter kernel size can be [1, 200, 1, 20]
2. Aggregate all convolution outputs to form an attention matrix \(s_a\in R^{n*m}\), where \(n\) is the number of words in the document, and \(m\) is the number of filters whose length is 1.
As to example above, we will get an output with the shape [32, 50, 1, 20], reshape it to [32, 50, 20]
3. Execute max pooling for each row of the attention matrix \(s_a\), which generates the attention vector \(v_a\in R^n\).
Then, we will get an output with the shape [ 32, 50, 1]
4. Transpose the document matrix \(s\) such that \(s^T\in R^{d*n}\), and multiply it with the attention
vector \(v_a\in R^n\), which generates the embedding attention vector \(v_e\in R^n\)
It means we will get an output 32 * 200.
How about the effect of embedding attention?
In this paper, we have not found the affection of embedding attention to model. However, I think it is same to self-attention method.