Paper: End-to-End Speaker-Dependent Voice Activity Detection gave us a method to use LSTM to implement speaker-dependent voice activity detection.
How to add speaker-dependent information to lstm?
Here is the model structure.
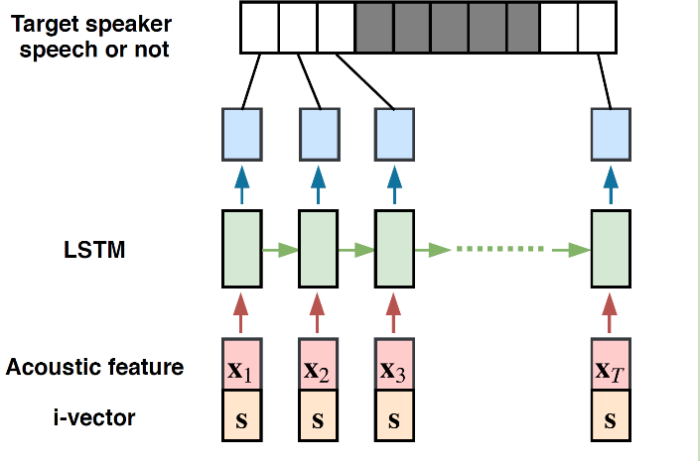
In this paper, i-vector is used as the speaker unique feature. Moreover, we also can use voiceprint.
From this structure, we can find speaker feature is added to input directly, however, it is not a good method. We may can use conditional layer normalization.