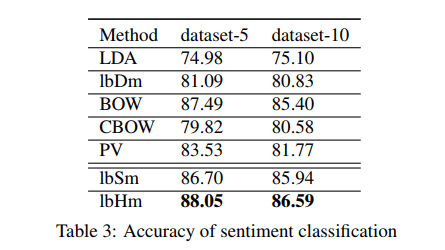
When we use word2vec or glove to learning word representations, word representations are able to capture syntactic and semantic regularities in text. However, it can not capture personalized information, such as sex, age or identification.
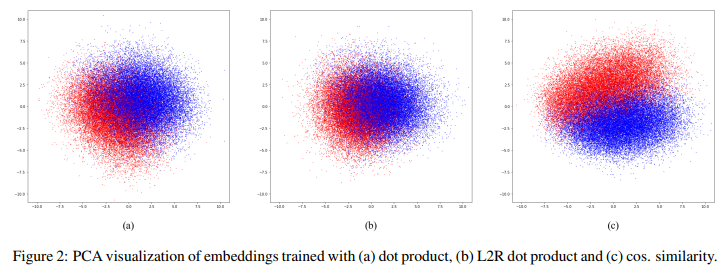
In order to implement document-level sentiment classification, each document must be mapped a dense, low dimensional vector in continuous vector space. In deep learning, we can use LSTM, CNN to model.