Devlin et al. (2019) produced 2 BERT models, for English and Chinese. To support other languages, they trained a multilingual BERT (mBERT)
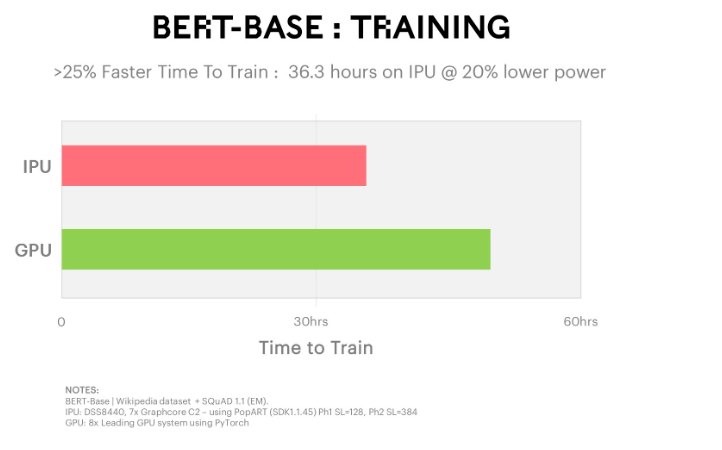
An integral part involved in developing various PLMs is providing NLU multitask benchmarks used to demonstrate the linguistic abilities of new models and approaches
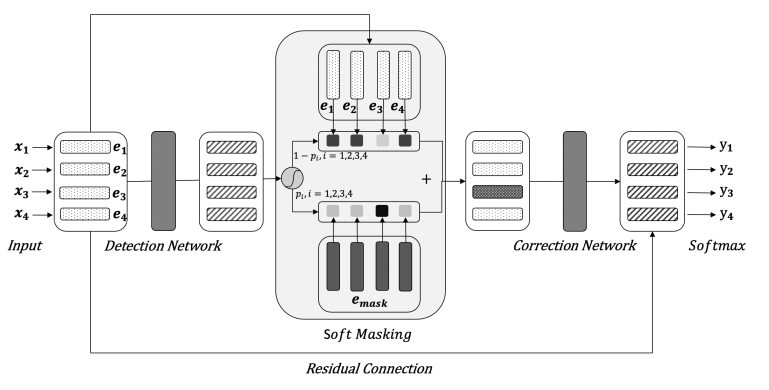
In NLP, we do not mask any input embeddings for Bert in text classifcation task. However, in paper: Spelling Error Correction with Soft-Masked BERT proposed a masked method.
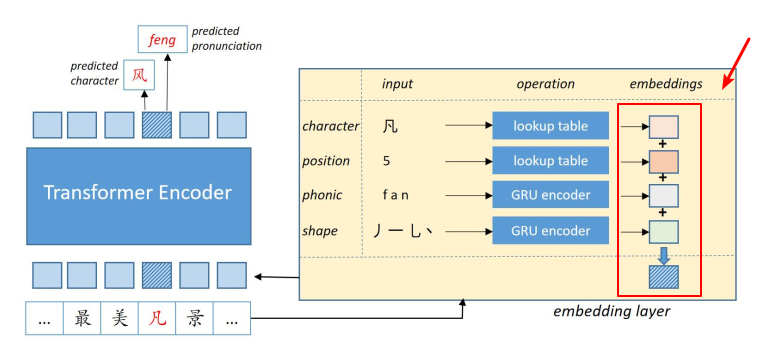
In this article, we will introduce a method to incorporate extra featrues into bert inputs to improve the performance of NLP task.
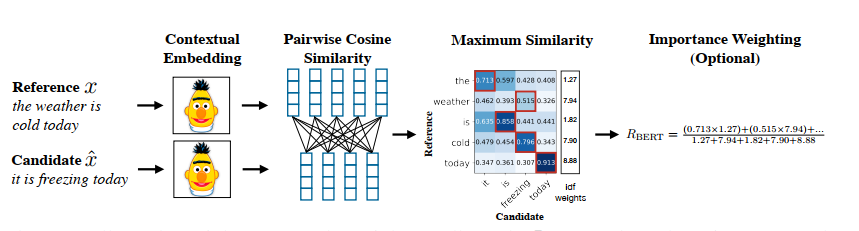
In this article, we will introduce a new metric for sentence similarity – BertScore, which has better performance than cosine similarity.
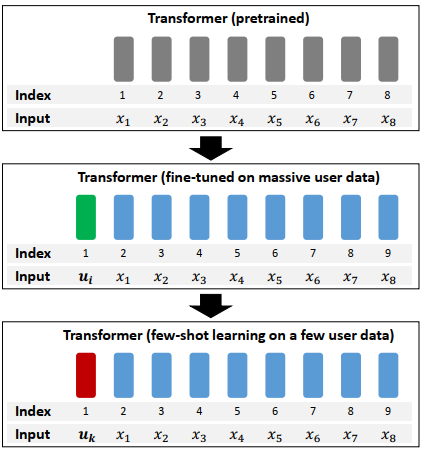
In this article, we will introduce how to generate specific vector by fine-tuning bert in few-shot learning.
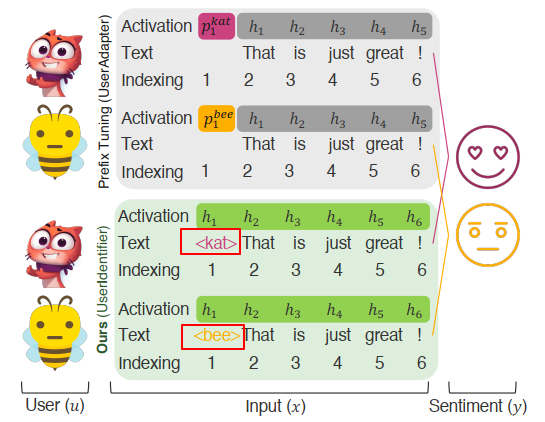
We can input a text sequence to bert model for classification. However, if this text sequence has a target text or object, how to use bert?
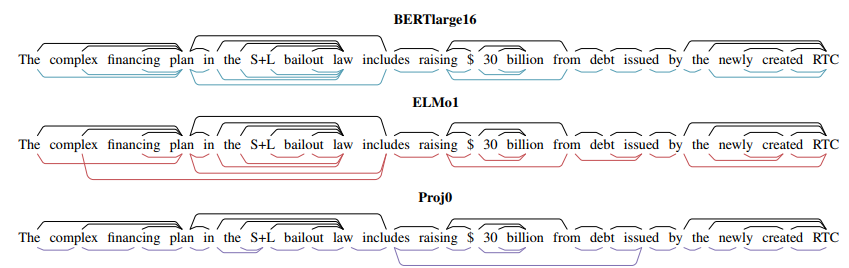
In this article, we can find representation generated from Bert or ELMo can encode syntax information.
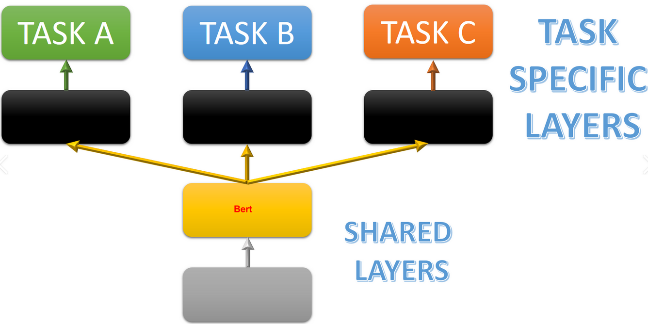
This tutorial will discuss how to use bert model for multi-task learning. You can build your custom model from this post.
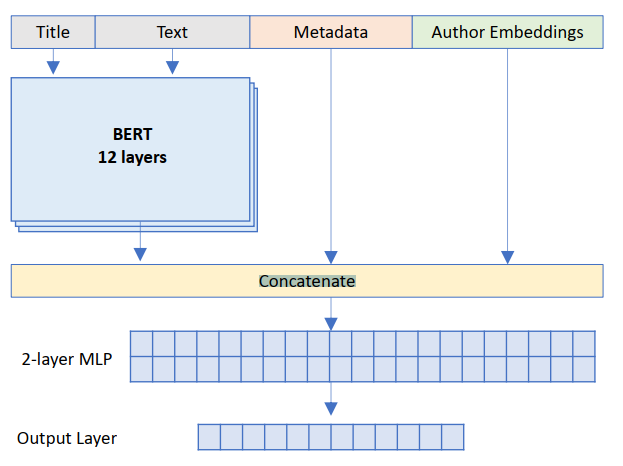
Bert is widely used in text classification, However, Bert only can extract text feature from a text sequence. If you have other features, how to combine them with Bert output to implement classification.