In order to implement document-level sentiment classification, each document must be mapped a dense, low dimensional vector in continuous vector space. In deep learning, we can use LSTM, CNN to model.
However, paper: Sentiment Classification using Document Embeddings trained with Cosine Similarity proposed a new method to create document vectors.
As to word2vec, we can use negative sampling to create word embeddings. In this paper, it also use this method to create document vectors.
The source code is here: https://github.com/tanthongtan/dv-cosine
How about the objective function?
In order to create document vector by training, we should build a objective function.
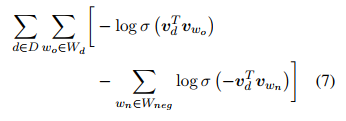
This objective function is a logistic regression.
The \(\sigma\) is the sigmoid function.
Understand Sigmoid Function: Properties and Derivative – Machine Learning Tutorial
There are also other objective functions:
L2R dot product
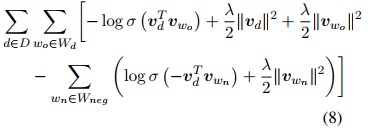
How about document embeddings?
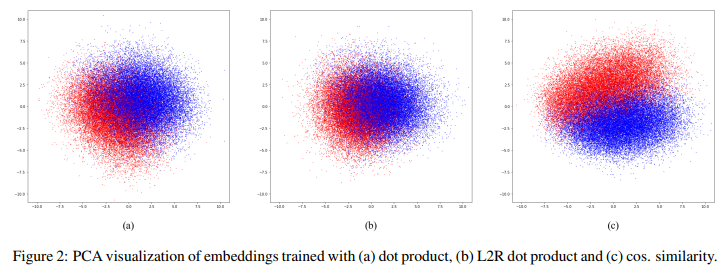
Here is the result:
Datasets used for Document-level Sentiment Analysis
IMDB dataset is used in this paper. This dataset contains 25,000 training documents, 25,000 test documents, and 50,000 unlabeled documents. The IMDB dataset is a binary sentiment classification dataset consisting of movie reviews retrieved from IMDB
Comparative Results
The comparative results are below: