Agreement loss is proposed in paper: Learning from Noisy Labels for Entity-Centric Information Extraction. It is a regularization method.
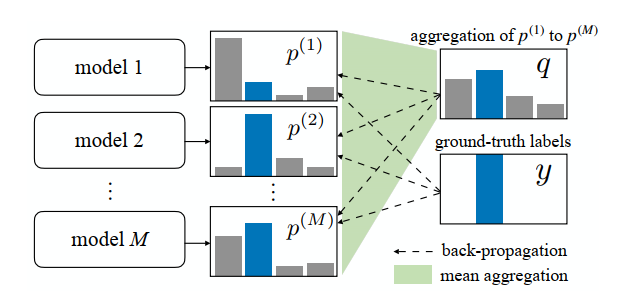
In this paper, M models are created and get M predicted distributions. Here \(M\geq2\)
We can implement agreement loss as follows:
Step 1: averaging M predictions
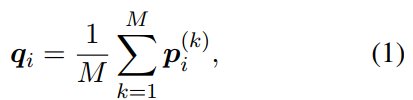
Of course, we also can use max-pooling or self attention method to calculate \(q_i\).
Step 2: building agreement loss
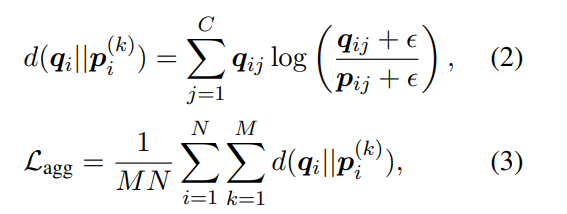
Here € is a small positive number to avoid division by zero.
Agreement loss will make M model predicted distribution be similar.
Step 3: Buliding finally loss
The final loss can be:
L = average_model_loss + λ*L_agg
λ is a hyperparameter, it can be 1.