Gradient-based methods provide alternatives to attention weights to compute the importance of a specific input feature. Despite having been widely utilized in other fields earlier (Ancona et al., 2018; Simonyan et al., 2013; Sundararajan et al., 2017; Smilkov et al., 2017), they have only recently become popular in NLP studies (Bastings and Filippova, 2020; Li et al., 2016; Yuan et al., 2019).
These methods are based on computing the firstorder derivative of the output logit \(y_c\) w.r.t. the input embedding \(h_i^0\) (initial hidden states), where c could be true class label to find the most important input features or the predicted class to interpret model’s behavior. After taking the norm of output derivatives, we get sensitivity (Ancona et al., 2018), which indicates the changes in model’s output with respect to the changes in specific input dimensions.
Instead, by multiplying gradients with input features, we arrive at gradient×input (Bastings and Filippova, 2020), also known as saliency, which also considers the direction of input vectors to determine the most important tokens. Since these scores are computed for each dimension of embedding vectors, an aggregation method such as L2 norm or mean is needed to produce one score per input token (Atanasova et al., 2020a):
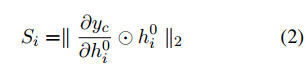
Reference
- Marco Ancona, Enea Ceolini, Cengiz Öztireli, and Markus Gross. 2018. Towards better understanding of gradient-based attribution methods for deep neural networks. In International Conference on Learning Representations.
- Karen Simonyan, Andrea Vedaldi, and Andrew Zisserman. 2013. Deep inside convolutional networks: Visualising image classification models and saliency maps. arXiv preprint arXiv:1312.6034.
- Mukund Sundararajan, Ankur Taly, and Qiqi Yan. 2017. Axiomatic attribution for deep networks. In Proceedings of the 34th International Conference on Machine Learning-Volume 70, pages 3319–3328.
- D Smilkov, N Thorat, B Kim, F Viégas, and M Wattenberg. 2017. Smoothgrad: removing noise by adding noise. arxiv. arXiv preprint arxiv:1706.03825.
- Jasmijn Bastings and Katja Filippova. 2020. The elephant in the interpretability room: Why use attention as explanation when we have saliency methods? In Proceedings of the Third BlackboxNLP Workshop on Analyzing and Interpreting Neural Networks for NLP, pages 149–155, Online. Association for Computational Linguistics.
- Jiwei Li, Xinlei Chen, Eduard Hovy, and Dan Jurafsky. 2016. Visualizing and understanding neural models in NLP. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 681–691, San Diego, California. Association for Computational Linguistics.
- Hao Yuan, Yongjun Chen, Xia Hu, and Shuiwang Ji. 2019. Interpreting deep models for text analysis via optimization and regularization methods. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 5717–5724.
- Pepa Atanasova, Jakob Grue Simonsen, Christina Lioma, and Isabelle Augenstein. 2020a. A diagnostic study of explainability techniques for text classification. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 3256–3274, Online. Association for Computational Linguistics.