We usually use word or sentence sequence feature based on BiLSTM or Bert for text classification. However, in paper: Sequential Matching Network: A New Architecture for Multi-turn Response Selection in Retrieval-Based Chatbots. It proposed a method that use word or sentence similarity matrix for classification.
Similarity Matrix
There are two methods to compute similarity matrix. They are:
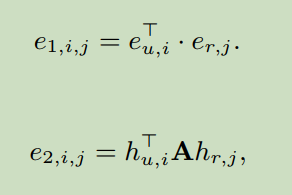
How to use similarity matrix for text classification?
One of key points is to use CNN.
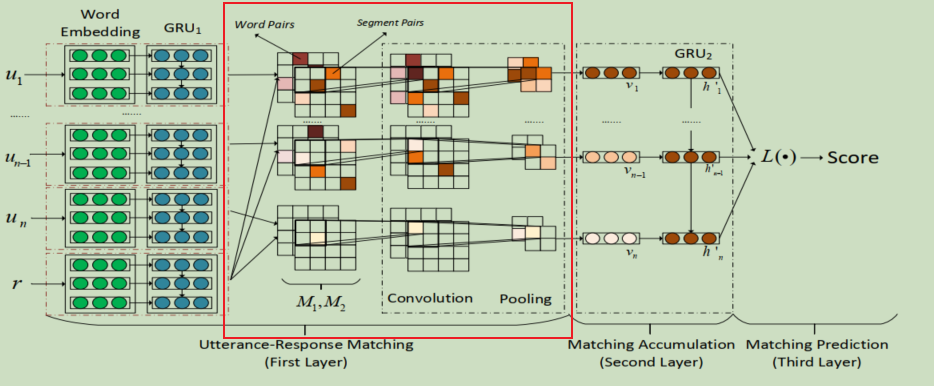
As to this paper, it also use a GRU to encode the sequential feature of similarity matrix. Because similarity matrix may ignore some useful information on word or sentence order.
Moreover, we also can use conditional layer normalization to improve it.