Self-attention is a core component of the Transformers (Vaswani et al., 2017) which looks for the relation between different positions of a single sequence of token representations \(x_1, …, x_n\) to build contextualized representations.
To this end, each input vector \(x_i\) is multiplied by the corresponding trainable matrices Q, K, and V to respectively produce query (\(q_i\)), key (\(k_i\)), and value (\(v_i\)) vectors. To construct the output representation \(z_i\), a series of weights is computed by the dot product of \( q_i\)with every \(k_j\) in all time steps. Before applying a softmax function, these values are divided by a scaling factor and then added to an attention mask vector m, which is zero for positions we wish to attend and -∞ (in practice, -10000) for padded tokens (Vaswani et al., 2017). Mathematically, for a single attention head, the weight attention from token \(x_i\) to token \(x_j\) in the same input sequence can be written as:
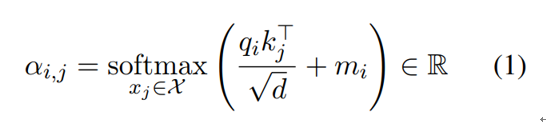
The time complexity for this is \(O(n^2)\) given the dot product \(q_ik_j^T\), where n is the input sequence length. This impedes the usage of self-attention based models in low-resource settings.
While self-attention is one of the most white-box components in transformer-based models, relying on raw attention weights as an explanation could be misleading given that they are not necessarily responsible for determining the contribution of each token in the final classifier’s decision (Jain and Wallace, 2019; Serrano and Smith, 2019; Abnar and Zuidema, 2020). This is based on the fact that raw attentions are being faithful to the local mixture of information in each layer and are unable to obtain a global perspective of the information flow through the entire model (Pascual et al., 2021)
Reference
- Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc.
- Sarthak Jain and Byron C. Wallace. 2019. Attention is not Explanation. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 3543–3556, Minneapolis, Minnesota. Association for Computational Linguistics.
- Sofia Serrano and Noah A. Smith. 2019. Is attention interpretable? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 2931–2951, Florence, Italy. Association for Computational Linguistics.
- Samira Abnar and Willem Zuidema. 2020. Quantifying attention flow in transformers. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4190–4197, Online. Association for Computational Linguistics.
- Damian Pascual, Gino Brunner, and Roger Wattenhofer. 2021. Telling BERT’s full story: from local attention to global aggregation. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, pages 105–124, Online. Association for Computational Linguistics.