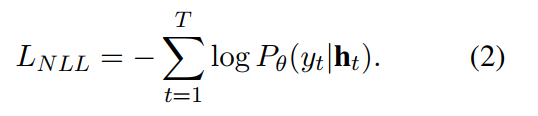Neural language generative models process text generation tasks as conditional language modeling, in which the model is typically trained by minimizing the negative log likelihood of the training data.
With a vocabulary of tokens \(V = {v_1, …, v_N}\) and embedding vectors \({w_1, …, w_N}\), where \(w_i\) corresponds to token \(v_i\), at every training step, the model obtains a mini-batch input and target text corpus pair \((x, y)\), where \(x_i\), \(y_i \in V\) , and \(y \in V^ T\) . The conditional probability for the target token \(y_t\), \(P_θ(y_t|h_t)\), where \(h_t\) is a context feature vector of the t-th position of the generated text conditioned by \((x, y_{<t})\), and\( θ\) denotes model parameters, which is defined as follows.
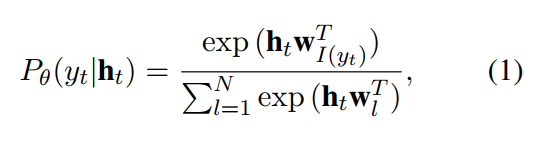
where w is the output token embedding which roles the weight of the output softmax layer, and I(yt) represents the index of token \(y_t\). The negative log likelihood loss for an input and target pair \((x, y)\), \(L_{NLL}\) is expressed as follows.