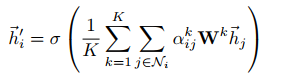In NLP, as to graph-structured data, we have to answer this question: How to get the current node output based on its neighborhood?
In paper: Graph Attention Networks proposed a method to answer this question.
How to get the current node output based on its neighborhood?
Usually, we may compute the attention score of the current node’s neighborhood, then add it to the current node.
For example:
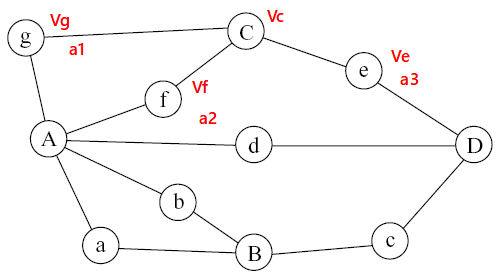
Here the current node is \(C\). Its vector is \(v_c\).
\(g\), \(f\) and \(e\) are its neighborhood. The vectors of their are \(v_g\), \(v_f\) and \(v_e\).
In order to get the output of \(C\), we can compute the attention score of \(g\), \(f\) and \(e\) based on \(v_c\) to get \(a_1\), \(a_2\) and \(a_3\).
Then we can add \(v_g\), \(v_f\) and \(v_e\) based on attention score to get output \(v_{gfe}\).
Finally, the final output of node \(C\) is:
\(o_c = v_c+v_{bef}\)
However, in paper: Graph Attention Networks, we will use a different method. It will create a virtual parent node to compute final output.
Graph Attention
The graph attention looks like:
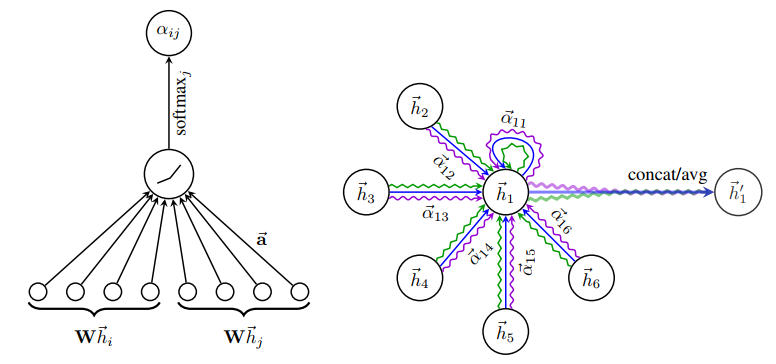
The key point is to computing the coefficient of current node and its neighborhood.
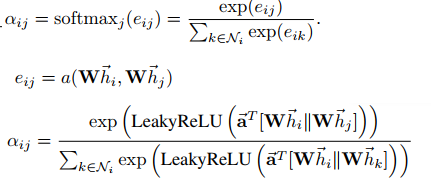
\(a_{ij}\) is the graph attention. However, we should notice: the parent node and its neighborhood share the same weight \(W\).
The current node output is:
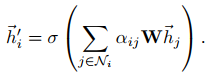
We also can use multi-head attention to improve the efficiency of graph attention.
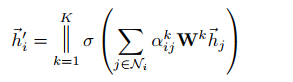
However, we shoul notice: we will average the \(k\) output to get the final output in the final layers.