In this article, we will introduce a new metric for sentence similarity – BertScore, which has better performance than cosine similarity.
Background
In order to evaluate the similarity between two sentences, we usually compute cosine similarity between them based on sentence vectors. However, this similarity may poor performance.
BertScore
BertScore is proposed in paper: BERTScore: Evaluating Text Generation with BERT
Different from cosine similarity, it will compute sentence similarity based on each token in a sentences.
It contians three metrics: \(R_{bert}\), \(P_{bert}\) and \(F_{bert}\). They can be computed as follows:
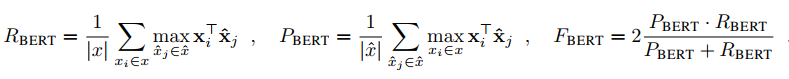
Here \(x\) and \(\hat{x}\) are all tokens in two different sentences.
As to each token representation, we can get by Bert or XLNet.
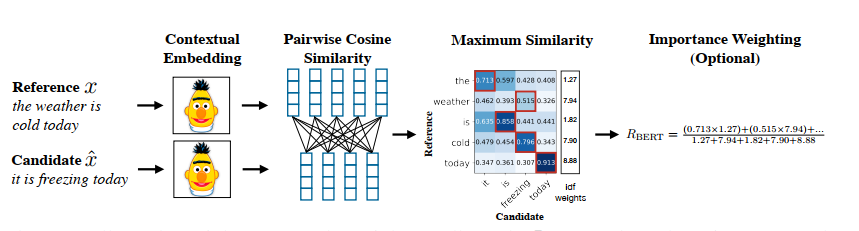
Token weight in BertScore
Formulas above, we can find all tokens have the same importance, however, rare words can be more indicative for sentence similarity than common words. This paper proposed a method to compute.
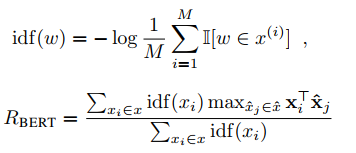
Here M is the count of reference sentences.
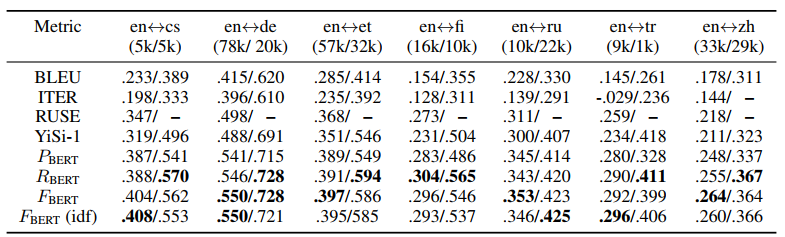
Result
There are some resuls in this paper, we can find the effectness of BertScore.