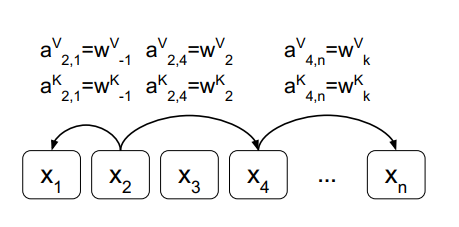
In this article, we will introduce how to computing self-attention with relative position representations in deep learning.
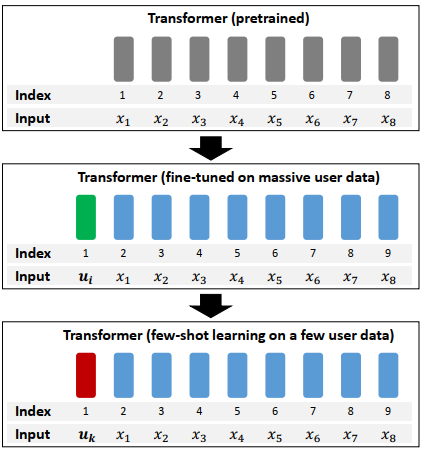
In this article, we will introduce how to generate specific vector by fine-tuning bert in few-shot learning.
Parametrization strategy can make the optimization more stable and improve the efficiency when file-tuning a model.
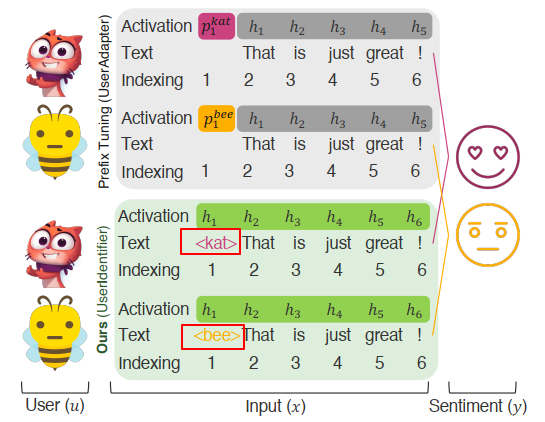
We can input a text sequence to bert model for classification. However, if this text sequence has a target text or object, how to use bert?
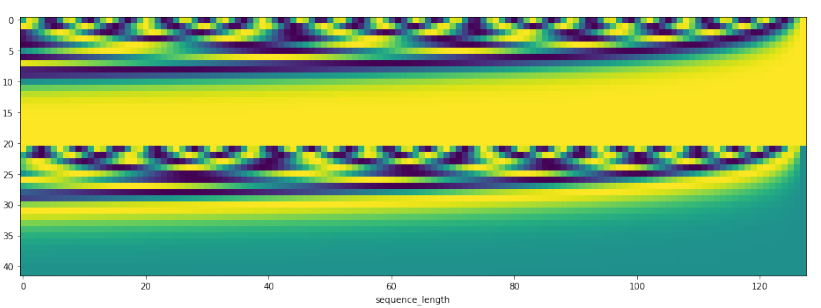
If you only have a scalar or number, how to convert it to be a vector for matrix operation? Paper Attention Is All You Need gives a method.
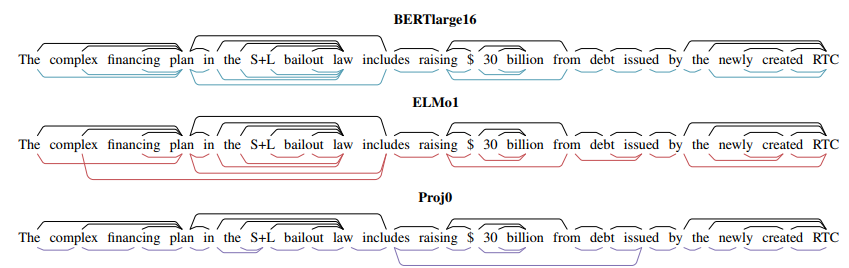
In this article, we can find representation generated from Bert or ELMo can encode syntax information.
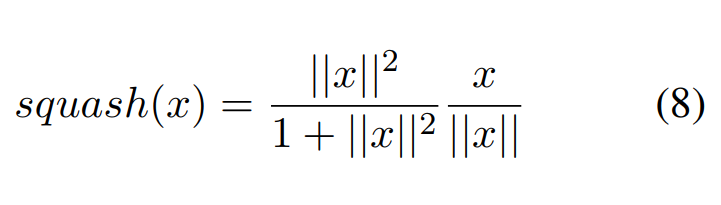
Squash function is a non-linear function that ensures the length of almost zero for short vectors and a length of slightly below 1 for long vectors.
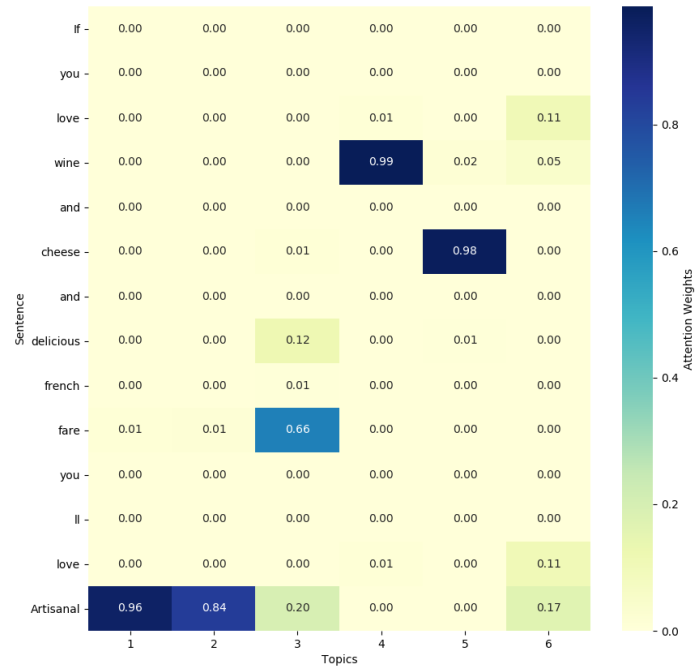
Topic attention is proposed in paper Aspect Category Detection via Topic-Attention Network, it can incorporate topic information in self-attention mechanism.
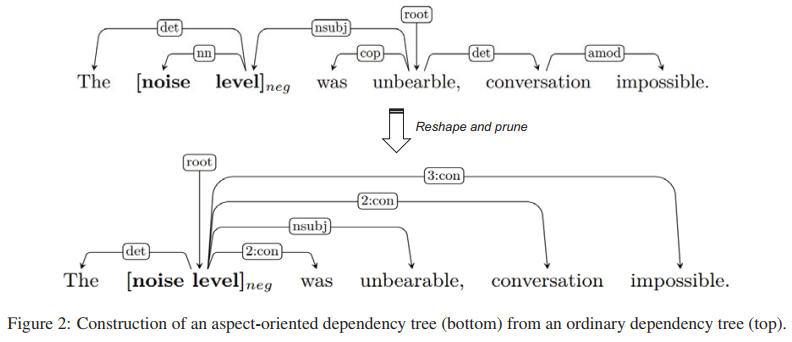
Generally, a dependency tree is not target-oriented, we can build a dependency tree for a sentence by some python libraries.
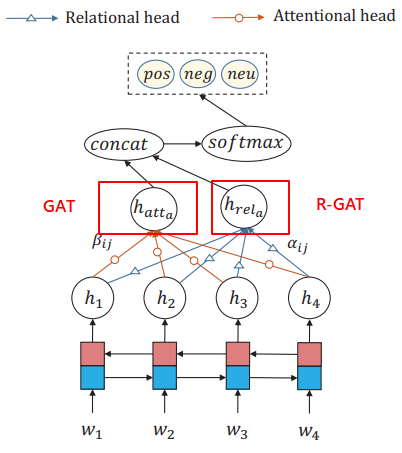
Relational Graph Attention Network is the extension of the original GAT, it is proposed in paper: Graph Attention Network