In this tutorial, we will introduce you how to incorporate multiple features to improve the model performance in deep learning.
In this article, we will discuss the random seed can affect the performance of neural network model in deep learning.
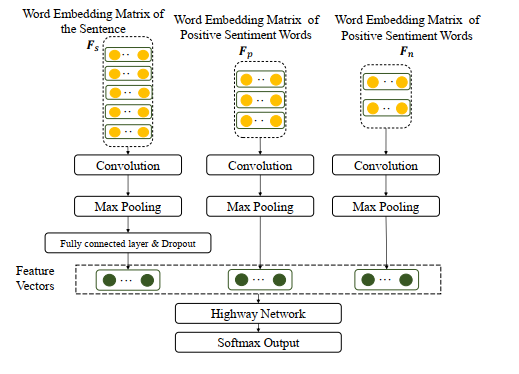
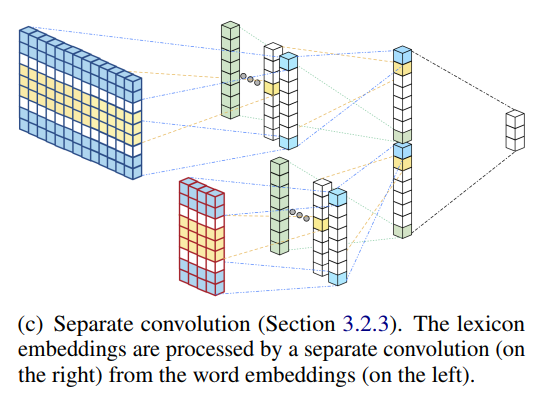
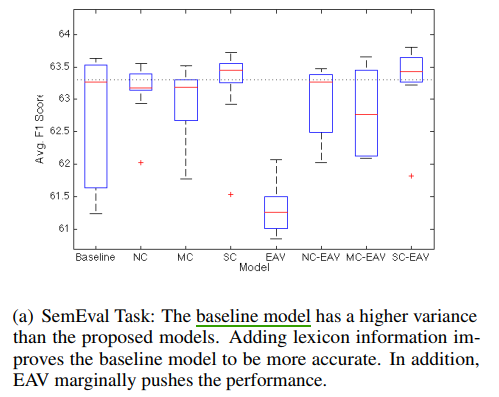
Sentiment lexicons contain some useful sentiment words, they can be used to sentiment classification with neural networks.
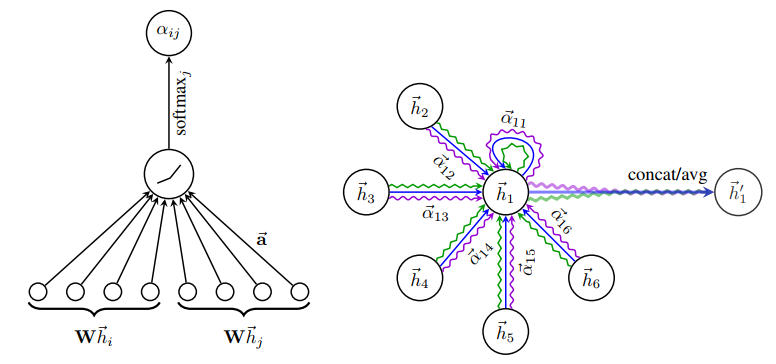
In NLP, as to graph-structured data, we have to answer this question: How to get the current node output based on its neighborhood?
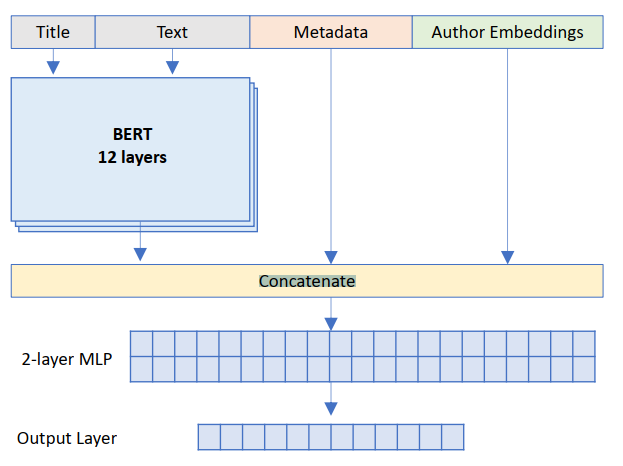
Bert is widely used in text classification, However, Bert only can extract text feature from a text sequence. If you have other features, how to combine them with Bert output to implement classification.
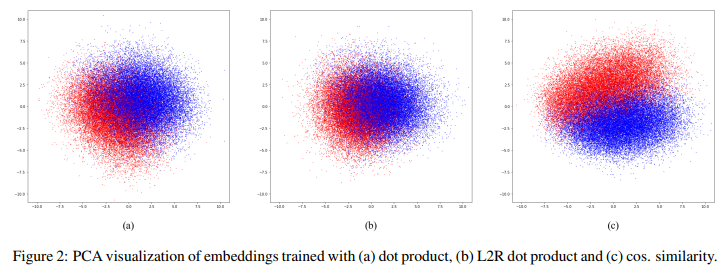
When we use word2vec or glove to learning word representations, word representations are able to capture syntactic and semantic regularities in text. However, it can not capture personalized information, such as sex, age or identification.
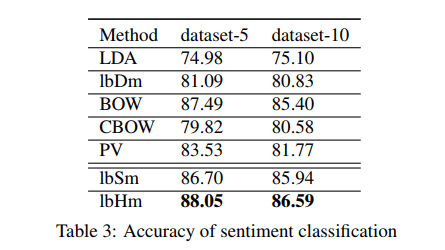
In order to implement document-level sentiment classification, each document must be mapped a dense, low dimensional vector in continuous vector space. In deep learning, we can use LSTM, CNN to model.

Label Attention is a kind of attention mechanism in deep learing, which integrates label feature attention. In this tutorial, we will use an paper: A Label Attention Model for ICD Coding from Clinical Text to introduce it.
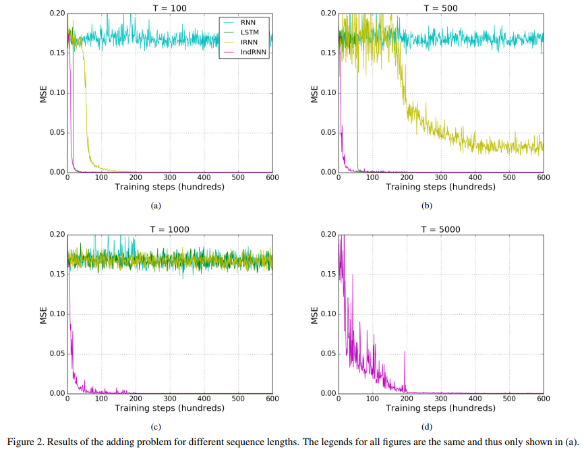
LSTM usually can handle about 200 length sequence effectively. However, if you should handle more than 200, for example 2000 length, how to do?
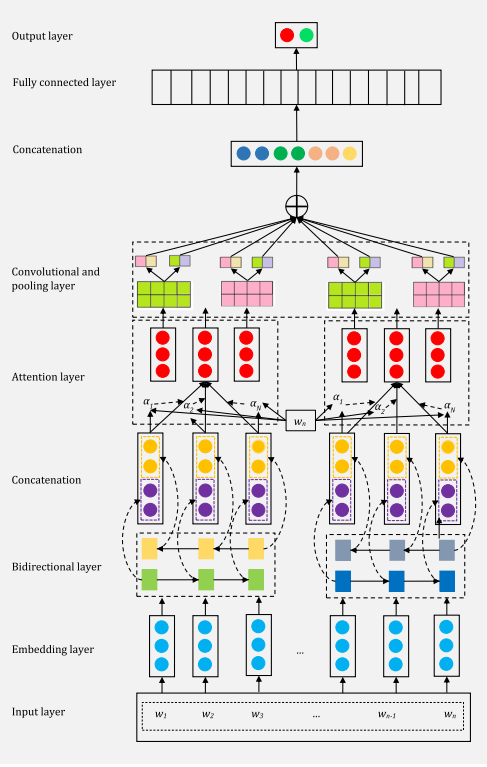
ABCDM is the tensorflow implementation of the paper: ABCDM: An Attention-based Bidirectional CNN-RNN Deep Model for sentiment analysis.ABCDM is the tensorflow implementation of the paper: ABCDM: An Attention-based Bidirectional CNN-RNN Deep Model for sentiment analysis.