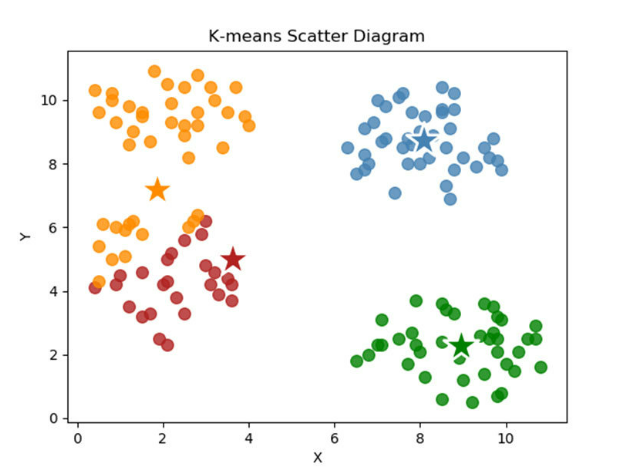
K-Means Clustering can partition unlabeled data based on distance into groups of similar datapoints automatically. The distance can be euclidean.

In this turorial, we will introcude how to implement a fast K-Means clustering in pytorch, we can use our gpu to speed up clustering.
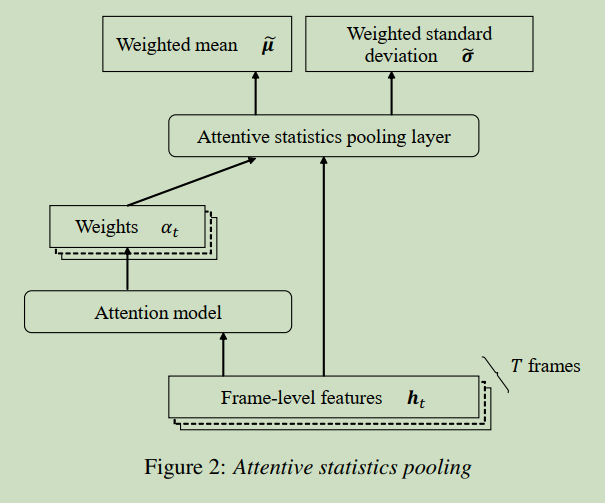
Attentive Statistics Pooling is proposed in paper: Attentive Statistics Pooling for Deep Speaker Embedding. In this article, we will introduce it for beginners.
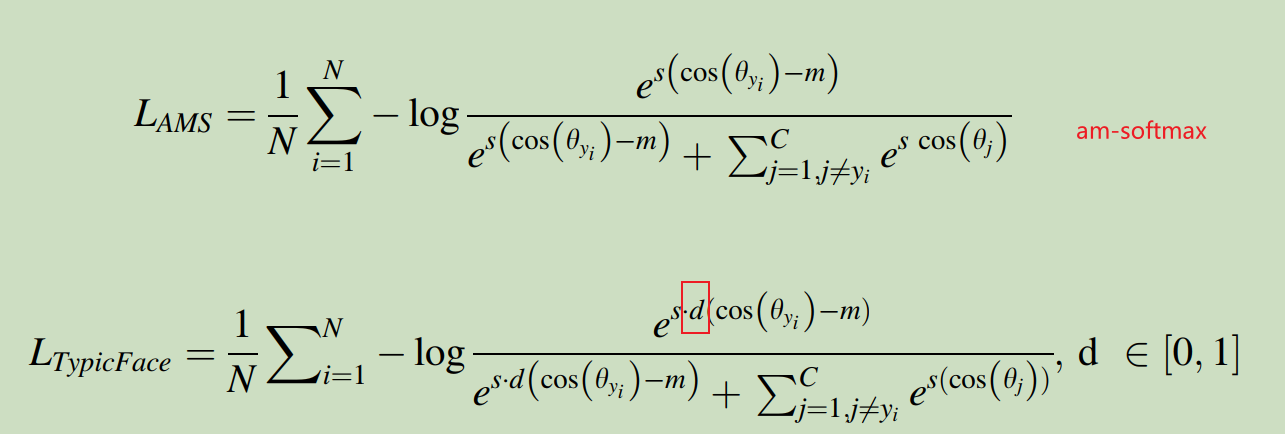
This method is proposed in paper: TypicFace: Dynamic Margin Cosine Loss for Deep Face Recognition. It improved AM-Softmax with a hyperparameter.
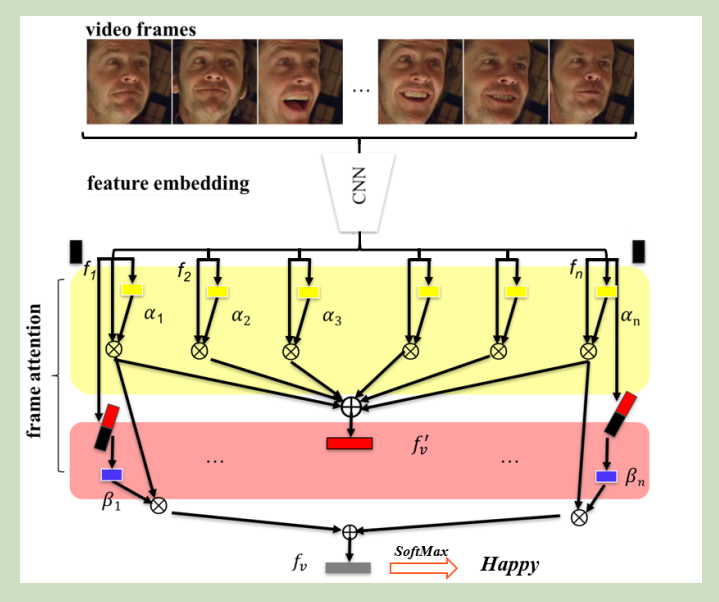
Relation attention method is often used to calculate the relation core between two object. For example: a query object and some samples.
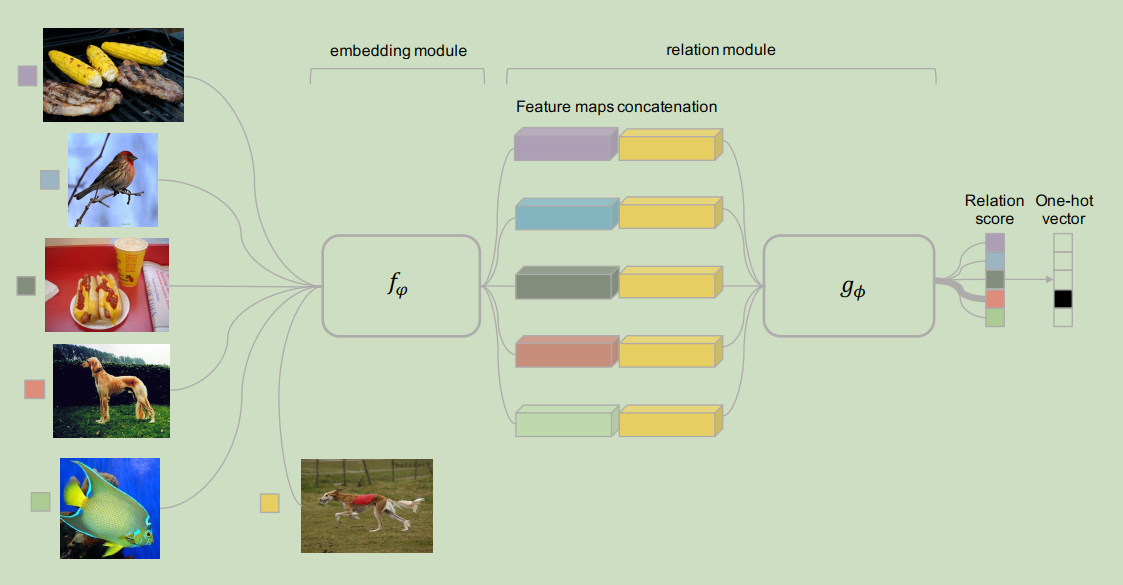
Relation attention network is proposed in paper: Learning to Compare: Relation Network for Few-Shot Learning. In this article, we will introduce it.
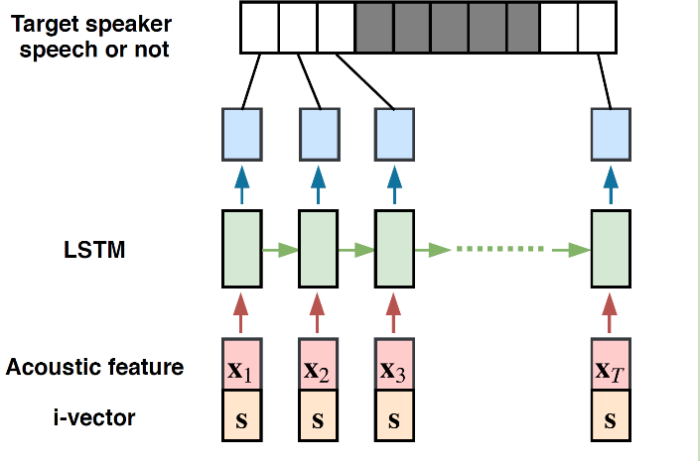
Paper: End-to-End Speaker-Dependent Voice Activity Detection gave us a method to use LSTM to implement speaker-dependent voice activity detection.
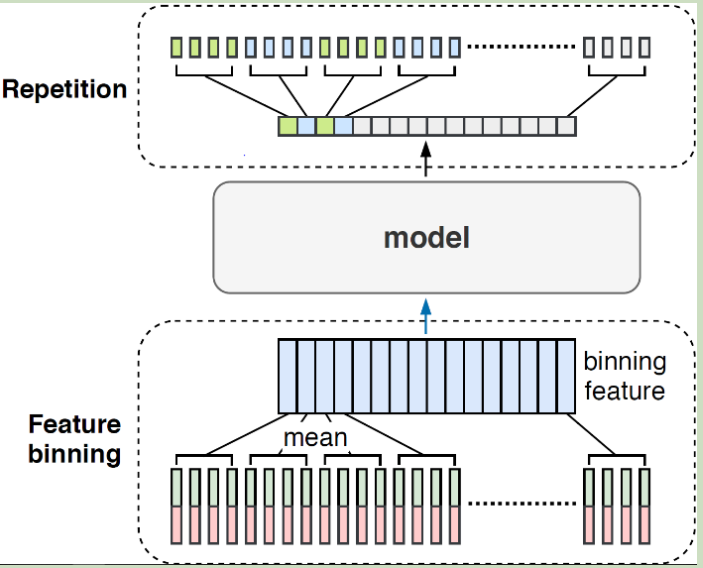
Voice Activity Detection is also called VAD, which aims to detect which voice part is spoken by persons. It need some silence and noise.

Pseudo label method is a simple but efficient way to improve text classification, it is a semi-supervised learning method.
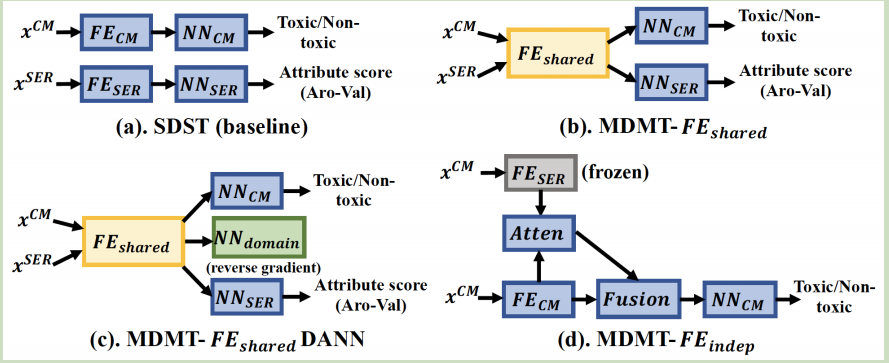
When building an AI model, we often use an auxiliary task to improve our main task performance. In this article, we will introduce three basic models.