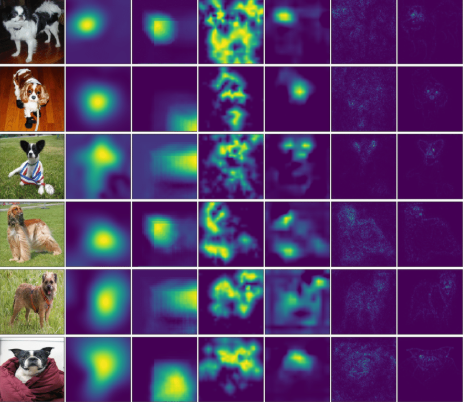
Gradient-based methods provide alternatives to attention weights to compute the importance of a specific input feature.
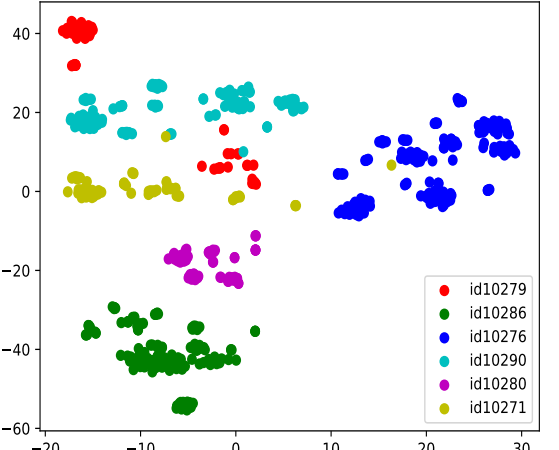
SimCLR directly maximizes the similarity between augmented positive pairs and minimizes the similarity of negative pairs
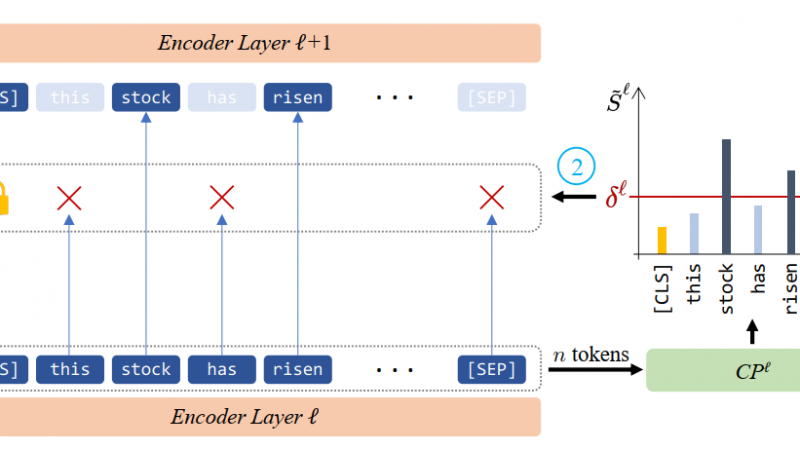
Self-attention is a core component of the Transformers (Vaswani et al., 2017) which looks for the relation between different positions of a single sequence of token representations
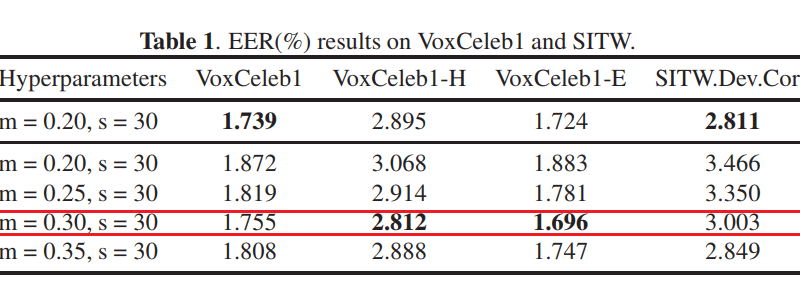
Real AM-Softmax loss function is an improvement of AM-Softmax. It is proposed in paper: Real Additive Margin Softmax for Speaker Verification.
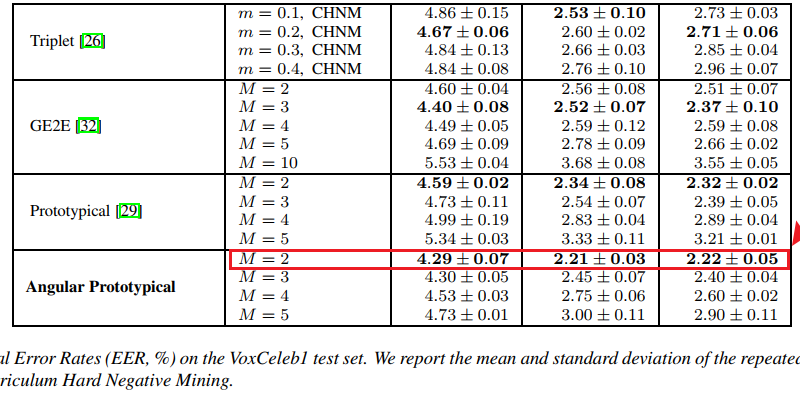
In this article, we will disucss which loss function will get the best performance in speaker recognition task.
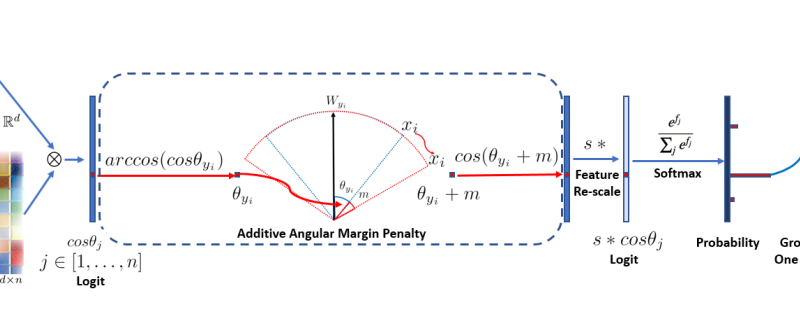
AAM-Softmax is also called ArcFace and is proposed in paper: ArcFace: Additive Angular Margin Loss for Deep Face Recognition.
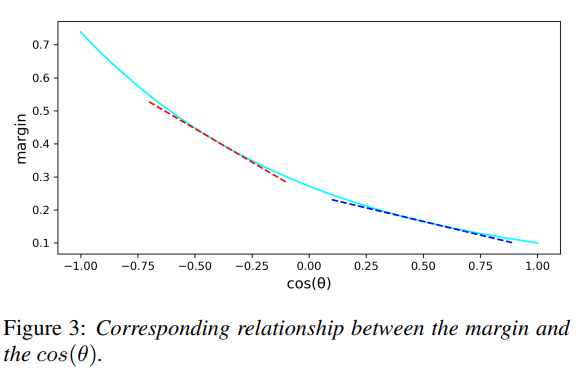
DAM-Softmax loss is an improvement of AM-Softmax, it is proposed in paper: Dynamic Margin Softmax Loss for Speaker Verification.
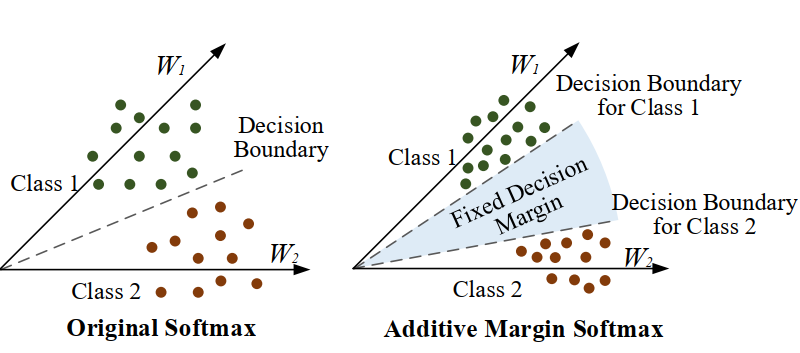
AM-Softmax Loss is also called additive margin softmax. It is an improvement of softmax loss and proposed in paper: Additive Margin Softmax for Face Verification.

OC-Softmax loss function is proposed in paper: One-class Learning Towards Synthetic Voice Spoofing Detection. It often be used in synthetic voice spoofing detection task.
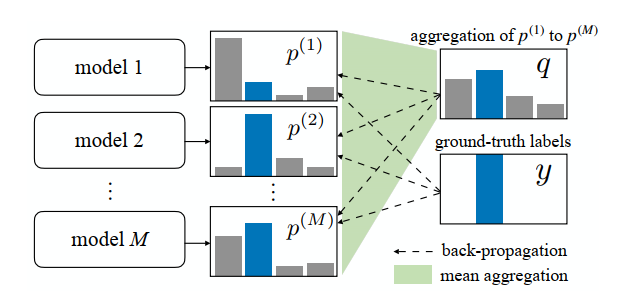
Agreement loss is proposed in paper: Learning from Noisy Labels for Entity-Centric Information Extraction. It is a regularization method.